
Guess your vote using Twitter
![]()
Initial note:This proyect was done just before the Spanish elections of November 10th 2019.
Goal: Can we guess the party that someone will vote just with their Twitter user?
We are importing data from Spanish twitter accounts and analizing them with some basic NLP. The goal is a very basic one: We get someone´s last 200 tweets (that´s the limit of the Twitter API) and we predict the party she/he might vote. Can we do this?
Stack used: Python, nltk (cleaning the data), pandas (managing all the dataframes), sklearn (predictions) and Twitter API (to extract the tweets).
Obtaining data
We need data to train our models. In other words, we need tweets from known voters of each party. This was the full pipeline to obtain the data. We just needed as input per each user:
- Twitter UserId
- Party that it belongs to (the flag)
Choosing flag users
We need Twitter users that are openly voters of each party. We selected the 6 parties that will have more votes in next elections (according to pools).
PP, Ciudadanos (CS), PSOE, UnidasPodemos (UP), VOX and MasPaís (MP).
From each party we obtained the tweets of:
- Official Twitter account of the party.
- Main polititian
- 5 other members of the party (taken from Senate/Parlament list). In case of MP we just googled
Data pipeline
The process that we followed was:
- Get all tweets from the user (Twitter API has a limit on 200 tweets)
- Store all Twitter info in 2 csv files (one with user info + another one with tweets info)
-
Clean tweets:
- Remove punctuation
- Save hashtag/user mentions/ emoticons into lists
- remove url, Spanish laugh,
- split tweet text into words
- stem the words (to keep only the root) and count vectorize them.
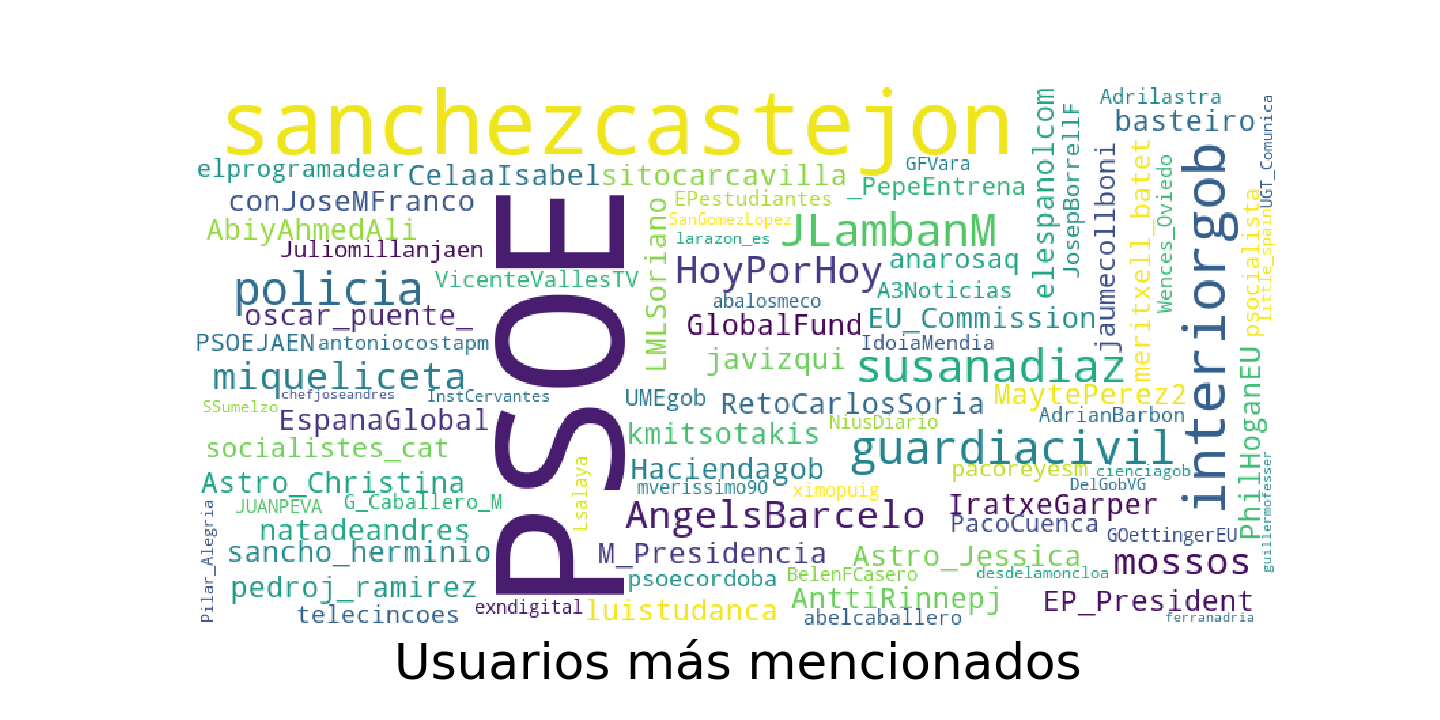
- Create a word cloud with most used words/hashtags/mentioned users
- Add this user to tweet DB (csv file)
At the end we have a file with all the users + another with all the tweets. Ah, and wordclouds to explain graphically a summary of the tweets of each user.


Choosing the best ML model
We train 2 different models to evaluate their performances: logistic regression and random forest.
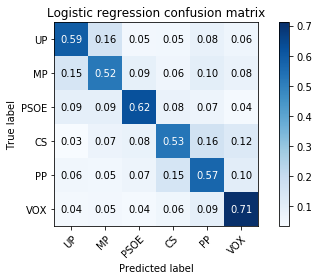
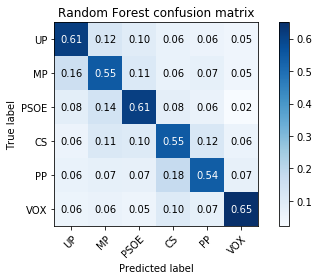
For each party, just by checking the confusion matrix, we can see how they get confused with other parties.
Confusion matrix
In here we show the confusion matrix of each model:
Some insights taken from the confusion matrix
So one can argue that:
- UP tweets can be confused with MP
- MP tweets can be confused with UP (up to 15% of the tweets look like UP).
- PSOE tweets are 2nd easiest to spot. (confused with UP and MP)
- CS tweets can be confused with PP and VOX
- PP tweets can be confused with CS and VOX
- VOX tweets are the easiest to spot in both models (although some times missclassified to PP or CS)
A surprising fact is that both models could tell if the author of the tweet was a right-wing or left-wing voter.
Recall and precission
 Both models are similar in accuracy, 59%.
Both models are similar in accuracy, 59%.
A reminder of recall and precission:
- recall is true positives/ predicted positives (true positives + false positives)
- precission is true positives/real positives (true positives + false negatives)
For email spam classifier, we want to minimize false positives (emails that are good emails but our classifier flags as spam). Therefore we want to maximize precission. For cancer detection, we want to minimize false negatives (people that have cancer but our classifier flags as negative). Therefore we want to maximize recall.
It would be then up to the user of these models, to decide which of the 2 to use in which case.
Try to guess the vote of a twitter user
Let’s try to predict the vote of a real user (me). We will extract my last 200 tweets (again, that’s the max of Twitter’s API) and classify them relating them to the closest party.
.")
The parties are ordered left to right by ideology. UP being farthest left and VOX being farthest right wing.
So apparently, according to the logistic regression model, 28% of my tweets are VOX-like. Whereas according to the random forest model, 46% of my tweets look like “Mas Pais” tweets.
Open questions
Question 1: Big question thrown here, if one writes like a party, does he/she think like that party? Does he/she want to vote them?
I don’t have the answer.
Question 2: Polititians of party X may talk different than voters of party X?
One thing to consider is that VOX and Mas Pais were the newest parties at that time. Completely opposites in ideology, but new. And since we are checking the content of the tweets, it could affect the fact that some of the people taken as voters where not politians when they wrote their tweets. On top of that, when we are checking the tweets of a normal user like me, maybe I write different than politians do?
How to improve
- It takes long time to compute. Try to run it on GNU or on AWS/GCP server.
- Take tweets from people that vote each party and are not politians. We need volunteers for this? Or at least people that are public voters of each party.
- Try to do it with a Neural Network.
TL;DR
- We used random forest and logistic regression to obtain the best prediction model.
- The accuracy of our predictions was low, lower than 60%.
- Interestingly enough, the model was able to tell between right-wing and left-wing parties.
- Since the accuracy is low, for a single user the 2 models predict different things. One should aim for recall/precission depending on his/her goal and choose one model over the other
Some related links
- Inspired by https://rodolfoferro.xyz/sentiment-analysis-on-trumps-tweets/
- NLP intro (in Spanish)
- Twitter API
Appendix: Some dead ends
When starting a project like this there are many promising paths to follow. Here I mention some of the dead ends:
Sentiment analysis
This is hard to do in Spanish. Most sentiment analysis (SE) libraries are using corpus in English. Therefore, we have several options:
- Translate our tweets to English to use SE from an already-built library like textblob or word2vec. This could work as a proof of concept, but not as a definitive version.
- Create our own corpus. Lots of classification needed
- Try to find a corpus in Spanish in the web. TASS was releasing until 2018 a corpus of Spanish tweets, but now it is hard to find it.
Blocking point for 1. Googletrans has a limit of 15k char per request. And might block the IP if you take too many requests… So it works up to some point… Any other way of translating?
Locating tweets in map
Most of the users have their location turned off. This is wise for a public figure, but for this poject means we cannot locate their tweets.